Chapter 7: The CUDA Gamble and the Gamers' "R&D Tax"
In the spring of 2026, a machine learning engineer who had just gotten his master's degree was making technology choices for his first job. The task was simple: train a mid-sized language model. He opened PyTorch, wrote a few lines of code, called torch.cuda.is_available() to confirm the GPU was online, and started training.
He didn't think about what happened underneath that line of code.
PyTorch called cuDNN—NVIDIA's deep neural network acceleration library. cuDNN called cuBLAS—NVIDIA's linear algebra library. cuBLAS compiled into PTX intermediate code, which was then instantly translated by the NVIDIA driver into SASS—the native machine instructions of that GPU. The entire pipeline, from the first line of Python to the switching of the very last transistor, had the exact same logo stamped on every single layer.
His manager said, "The company budget is tight, and AMD's GPUs are 40% cheaper. Can we switch?"
He tried. He changed torch.cuda to torch.hip. The first error appeared in a convolution kernel within cuDNN—AMD's equivalent, MIOpen, didn't support that specific data layout format. He worked around it. The second error appeared in multi-GPU communication—NVIDIA's NCCL library had no peer equivalent on AMD, AMD's own RCCL was a notch slower, and under certain topologies, it simply crashed. He spent three days tracing the issue and found it was a race condition in the driver layer, marked by AMD's ROCm team on GitHub as a "known issue, expected to be fixed in the next release."
Two weeks later, he told his manager: "We can't switch."
He treated this as an engineering problem—AMD's software wasn't mature enough yet, and maybe it would be fine if they waited two more years.
No.
AMD's ROCm isn't "not mature enough yet." It has been chasing for ten years, and it still hasn't caught up. Not because AMD's engineers are worse than NVIDIA's, but because what they are facing isn't a lock; it's a prison four layers deep. And you—everyone who has ever trained a model with PyTorch—have been living inside it since your first day of grad school.
The previous chapter told the story of how a lock was pried open. DirectX locked PC gaming for thirty years, and Valve bypassed it with Proton. After reading that chapter, you might feel: any lock can be pried open, as long as someone is determined enough.
This chapter is going to shatter that illusion.
I. Motive for the Crime
In 2003, a Stanford University PhD student named Ian Buck published something. It wasn't a graphics card, it wasn't a game—it was a programming language.
It was called Brook.
Buck observed a fact in the Stanford graphics lab: inside a GPU are hundreds of tiny cores, each capable of floating-point operations, and combined, their computing power far exceeds the fastest CPU of the time. But these cores only recognized graphics APIs—they were tied down by hardware design to the single task of "drawing pixels." What if they could be used to calculate other things—matrix multiplication, physics simulations, protein folding?
Brook was the answer he came up with: a language allowing programmers to use C-like syntax to throw general-purpose computing tasks onto the GPU. The concept was beautiful, but it had a fatal flaw: Brook had to disguise all computing tasks as graphic rendering instructions—because the GPU hardware of that era only recognized graphics APIs. You want to calculate a matrix multiplication? You first have to pretend it's a triangular texture, and then use an OpenGL shader to "render" it. Low efficiency, many restrictions, and few things it could actually do.
Buck got his degree thanks to Brook. Then Jensen Huang personally invited him to join NVIDIA.
In 2004, Buck entered NVIDIA. Jensen Huang looked at Buck's research, and he didn't see an academic report—he saw a seam. There are hundreds of tiny cores inside a GPU, each capable of floating-point operations, but the hardware design forced them to only draw pictures. If this restriction were removed—allowing those cores to do any computation—the GPU would transform from a graphics card into a supercomputer.
But the cost of removing that restriction was massive. It meant redesigning the entire architecture of the GPU: the instruction set had to change, the memory model had to change, the thread scheduler had to change. And these changes wouldn't make games run any faster—games only needed to draw pictures; they didn't need general-purpose computing. In other words, after making these changes, gamers wouldn't get any benefits, but NVIDIA would have to pay a massive R&D cost for them.
Jensen Huang had Buck lead a team to burn the concept of Brook directly into the hardware of the next-generation GPU. Not simulated in software, not done via shader hacks—but carving true general-purpose compute units into the silicon, allowing every core to execute arbitrary C code.
On November 8, 2006, the GeForce 8800 GTX launched. Codenamed G80. $599. 128 stream processors, 681 million transistors, 90-nanometer process.
What gamers saw was: the first graphics card in history to support DirectX 10, delivering a leap in visual quality that left them stunned.
What gamers didn't see was: inside those 128 stream processors, every single one had been redesigned—they didn't just calculate pixels; they could calculate anything. Matrix multiplication, Fourier transforms, fluid dynamics simulations, molecular dynamics—any problem you could write as parallel code could be thrown onto it.
Seven months later, on June 26, 2007, NVIDIA released the CUDA Toolkit 1.0—a set of development tools allowing programmers to write general-purpose computing programs directly in C on the GPU.
No gamers noticed. No gaming media reported on it. For 99% of GeForce 8800 GTX users, CUDA was something that didn't exist. They spent $599 to buy a graphics card to play games, not to run scientific calculations.
But inside their $599, a portion was taken to amortize the R&D cost of the general-purpose compute cores.
Every GeForce sold had hardware built in that gamers wouldn't use, but the scientific research community would use in the future. NVIDIA didn't explain this to anyone. It didn't need to. It just needed to keep selling gaming graphics cards—the more it sold, the thinner the general-purpose computing R&D costs were spread, and the lower the risk.
The interlude defined a type of person—someone who can see through the seams between the hardware instruction set, the software API, and the upper-level applications. Jensen Huang is the archetype of this kind of person. He could see the seam between the GPU's graphics cores and general-purpose computing. His bet was: let the gamers raise this seam for me first, and wait for the day someone comes to claim it.
But we must pause here and ask a question: NVIDIA is not Valve.
The previous chapter explicitly pointed out that Valve could withstand the failure of Steam Machines and continue investing in Linux because it is a private company—no shareholders, no Wall Street analysts asking every quarter where the ROI is. But NVIDIA had already gone public in January 1999. It was a publicly traded company listed on NASDAQ. The R&D costs of CUDA caused NVIDIA's market cap to drop from roughly $8 billion to under $1.5 billion. Wall Street's reaction wasn't questioning; it was silence—something far more terrifying than questioning.
How could Jensen Huang withstand that?
The answer starts from a thread buried in Chapter 4.
The end of Chapter 4 mentioned: NVIDIA supplied the GPU for the original Xbox in 2001—codenamed NV2A, based on the GeForce 3 architecture. That was NVIDIA's first taste of the console market. The taste was bitter. Microsoft locked the chip price in the contract and demanded NVIDIA lower the price year by year. Jensen Huang refused. The relationship went from cold to arbitration, ultimately reaching a settlement in February 2003. But settlement is not reconciliation. In August 2003, Microsoft announced the GPU for the Xbox 360 would switch to ATI.
NVIDIA was kicked out of the living room.
From the perspective of business textbooks, this was a failure. A console GPU is a stable order pipeline stretching seven to ten years—Chapter 8 will expand on this. Losing Microsoft as a client meant losing a long-term meal ticket for tens of millions of units shipped.
But in hindsight, being kicked out was the best thing that ever happened in Jensen Huang's career.
There are three reasons.
First, a console GPU is a thankless job. The console manufacturer asks you to make the chip into a semi-custom SoC, stuff it into the chassis they designed, run it according to their thermal budget, and then lower the price every year. Your top engineers aren't pursuing breakthroughs in the next generation architecture—they are saving costs for Microsoft. If NVIDIA were still making the GPU for the Xbox 360, the engineers who were supposed to be designing CUDA cores between 2004 and 2006 would likely have been locked into the drudgery of compressing costs for Microsoft.
Second, the profit structure of PC graphics cards is on an entirely better level than console GPUs. Microsoft felt a console chip costing a few dozen dollars was too expensive. But PC gamers were willing to spend $599 for a GeForce 8800 GTX—more than a dozen times the unit price of a console GPU. The profit Microsoft refused to give, gamers handed over with both hands. These profits were the true reason CUDA could burn money for ten years without bankrupting NVIDIA. Jensen Huang hid the R&D cost of CUDA inside the gross margin of every GeForce—gamers couldn't see it, and Wall Street didn't understand hardware design well enough to know that those "general-purpose compute cores" were things gamers didn't use. The "R&D Tax" isn't just a metaphor. It was Jensen Huang's financial sleight of hand to pull the wool over everyone's eyes.
Third, losing the living room forced Jensen Huang to think about a question he originally didn't need to ask: Besides drawing games, what else can a GPU do? If NVIDIA still had Microsoft's long-term meal ticket, this question might never have been taken seriously. But the meal ticket was gone. Jensen Huang had to find a second life for the GPU outside of gaming. Ian Buck's Brook was the starting point of that life.
There is a suffocatingly ironic boomerang here.
In 2002, Microsoft fell out with NVIDIA to save a few dollars in cost on every Xbox chip. Those few dollars multiplied by tens of millions of Xboxes was a dispute worth roughly a few hundred million dollars. Microsoft felt it won—it built the Xbox 360 with cheaper ATI chips and sold better than the original.
Twenty years later, in 2023, Microsoft placed an order with NVIDIA. Not for a few hundred million dollars—but billions of dollars. Tens of thousands of H100s and subsequent B200s, used to train the large language models of OpenAI, which it had invested $13 billion into. The price of every single card was hundreds of times the cost of that Xbox GPU back then.
The money Microsoft saved by kicking out NVIDIA back then because it was "too expensive" was now being vomited back, principal plus interest. And it was vomiting it back on its knees—because CUDA's four layers of locks meant that even if Microsoft wanted to change suppliers, it couldn't.
Microsoft was the indirect catalyst for the CUDA monopoly. It kicked out NVIDIA, forcing Jensen Huang back to the PC. Retreating to the PC allowed NVIDIA to earn the profit to fund CUDA. CUDA grew into a four-layer-deep prison, and Microsoft itself became the biggest prisoner inside it.
For this "someday," he waited six years.
II. Forging the Weapon
CUDA is not an API.
Chapter 2's DirectX is an API. It does one thing: it allows game programmers to use a unified set of function calls to drive GPUs from different vendors to draw pictures. DirectX is a layer—a layer of interface sandwiched between the game engine and the GPU driver.
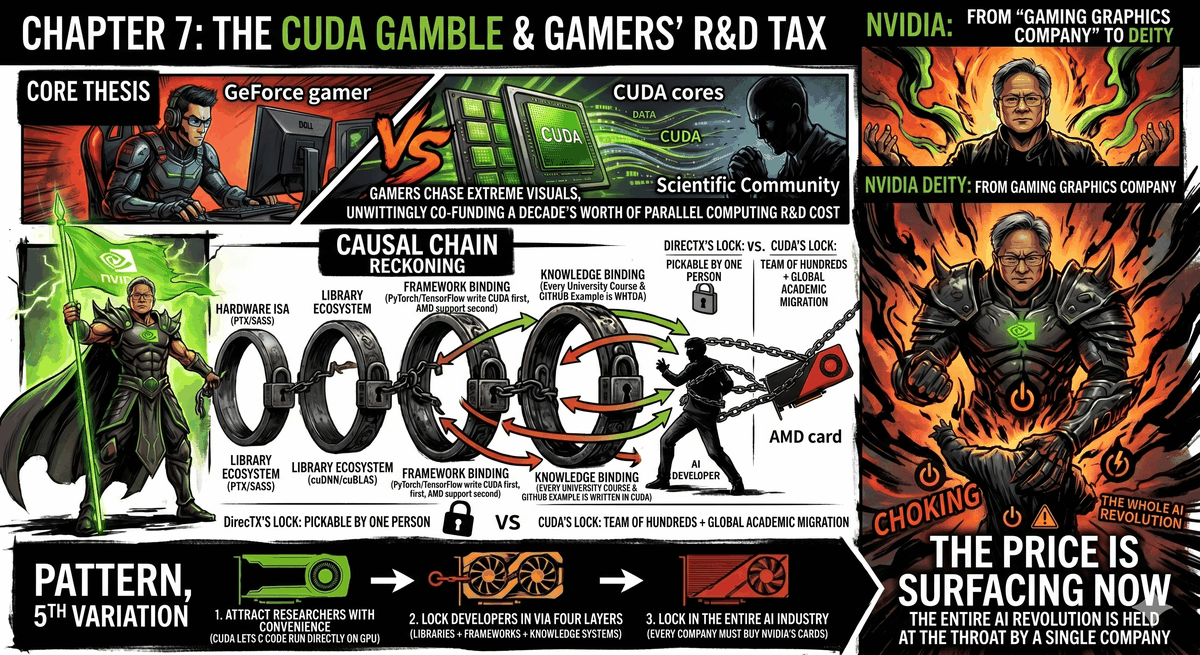
CUDA is not a layer. CUDA is a tower of four layers stacked together. Every layer has its own lock, every lock operates independently, and together they form an almost inescapable prison.
Layer One: The Hardware Instruction Set.
NVIDIA GPUs have their own native instruction sets—PTX (Parallel Thread Execution) is the intermediate representation layer, and SASS is the lowest-level machine code. When you write a piece of CUDA code, the compiler turns it into PTX, and then NVIDIA's driver translates the PTX into the SASS of your specific GPU model at runtime.
This works on the same principle as an x86 CPU: your code ultimately has to become instructions that chip understands. But the difference is that the x86 instruction set is public—both Intel and AMD implement the same instruction set, so your program can run on both companies' CPUs. NVIDIA's PTX and SASS are proprietary. AMD's GPUs have a completely different instruction set architecture. You have no way of taking a compiled piece of CUDA code and running it on an AMD GPU, just like you can't shove a CD into a tape recorder to play it.
Layer Two: Compute Libraries.
An AI researcher won't write a GPU kernel for matrix multiplication themselves—it's too slow, too prone to errors, and someone has already done it. They will call cuBLAS—NVIDIA's linear algebra acceleration library. Training a neural network? cuDNN—NVIDIA's acceleration library optimized for deep learning convolutions, normalizations, and activation functions. Doing a Fourier transform? cuFFT. Doing sparse matrix calculations? cuSPARSE. Communication between multiple GPUs? NCCL.
Behind every library is an engineering team of dozens to hundreds of people who have spent five or ten years performing extreme optimization targeting the microarchitecture of every generation of NVIDIA GPUs. The exact same matrix multiplication call, running the cuBLAS version, will automatically select the best algorithm based on your GPU model, matrix size, and data type—these algorithms were hand-tuned one by one by engineers, not auto-generated by programs.
Does AMD have corresponding libraries? Yes. rocBLAS, MIOpen, rocFFT—the names match up, the functions roughly match up. But they started nearly a decade later, and the target they are chasing keeps running every year. By 2026, cuBLAS had gone through over a dozen major version iterations. What rocBLAS has to chase isn't just today's cuBLAS, but also cuBLAS's roadmap for the next three years.
They chase, but they can't catch up. Because NVIDIA has something AMD doesn't: Every AI researcher in the world is using cuBLAS to run experiments every day, reporting bugs, requesting features, and contributing performance data. This feedback loop is something rocBLAS cannot buy—because too few people use rocBLAS.
Layer Three: Framework Binding.
PyTorch. TensorFlow. JAX.
The three major frameworks used by the global AI research community in 2026. All of them wrote their CUDA backends first, and patched in AMD support later.
This sentence sounds like a scheduling issue—which one to do first and which later. It's not. It's an issue of deep binding. The core operators of PyTorch—those low-level functions doing forward passes, backward passes, and gradient updates—were originally written in CUDA. They don't call an abstract GPU API and then adapt to CUDA—they are written directly using CUDA's memory model, CUDA's thread hierarchy, and CUDA's synchronization primitives. AMD's backend is added on afterward; essentially, it is a translation layer that translates PyTorch's CUDA calls into AMD's HIP calls.
How much can translation achieve? Basic functions, yes. But edge cases—a rare tensor shape triggering a fast path unique to NVIDIA in cuDNN, a distributed training strategy relying on a specific behavior of NCCL, a custom CUDA kernel using instructions unique to NVIDIA—these are the places where it breaks.
Inside the training code written by an AI researcher, there are over a dozen implicit CUDA dependencies. They weren't written by the researcher—they were called by PyTorch on their behalf. They write model.train() in their code, and PyTorch calls cuDNN's convolution kernel, cuBLAS's matrix multiplication, and NCCL's gradient synchronization for them. They have absolutely no idea they are using CUDA—just like the Steam Deck player in Chapter 6 doesn't know they are using Linux. The difference is, the Steam Deck player can afford not to care what's underneath; the AI researcher only realizes where they are locked in the moment they think about switching GPUs.
Layer Four: Knowledge Binding.
This is the deepest layer, and the least visible one.
GPU computing courses at universities worldwide—taught using CUDA. Textbooks—written with CUDA examples. Experimental code for academic papers—hosted on GitHub, implemented in CUDA. Q&A on Stack Overflow about GPU acceleration—there are fifty times more answers for CUDA than for ROCm. From the very first day a PhD student enrolls, the parallel computing language they learn is CUDA, the code attached to the papers they read is CUDA, the answers to the questions they ask are CUDA.
Five years later, they graduate. They join an AI company. Their way of thinking—how to partition data, how to schedule threads, how to minimize memory movement—has all been forged entirely by CUDA's mental model. If you tell them to "switch to AMD," they don't just need to switch toolchains—they need to relearn an entire way of thinking.
And they won't. Because their colleagues all use CUDA too. The reviewers of their papers use CUDA too. Their next job interview will ask about CUDA too.
This is knowledge lock-in. It doesn't rely on any contracts, any patents, or any commercial terms. It relies on an entire generation of engineers growing up within the exact same set of tools.
Four layers of locks. Hardware instruction sets, library ecosystems, framework binding, knowledge binding. Every layer operates independently, and every layer has its own moat. If you pry open the first layer (making your own GPU instruction set), the second layer is still there (no equivalent libraries). If you catch up on the second layer (spending ten years writing equivalent libraries), the third layer is still there (the framework's core code is still written for CUDA first). If you convince framework developers to treat you equally (the third layer), the fourth layer is still there—a million AI engineers already thinking in CUDA won't follow you just because you built a good set of tools.
This prison has no explicit door. It is enclosed by four mutually reinforcing walls.
III. Why It Can't Be Pried Open
After reading the previous chapter, you might think: No matter how hard CUDA is to pry open, it's just another DirectX—find an engineer determined enough, spend a few years building a translation layer, and you can eventually bypass it.
You can't.
Because the locks of DirectX and CUDA are of completely different depths.
What DirectX locks is one layer—a layer of graphics API. Though its behavior is complex, it is fundamentally a set of input-output mappings: the game issues a Direct3D call, expecting a certain result to appear on the screen. Most of these mappings are documented, and the rest can be reverse-engineered. The developer of DXVK, Philip Rebohle—a single person—could kick off that counterattack. Because he only needed to do one thing: observe DirectX's behavior and replicate it using Vulkan. Tedious, but feasible.
What CUDA locks is not one layer. It is four layers.
AMD tried translation. It made HIP—a set of tools that can automatically convert most CUDA source code into AMD code. Surface-level conversion can indeed be done. But the moment it hits cuDNN—a binary library without source code—HIP breaks. You have no way of translating something when you can't see its internals. AMD could only write a functionally equivalent MIOpen from scratch, and then spend years chasing the biannual updates of cuDNN.
The deeper problem is: even if AMD caught up at the library layer—assuming MIOpen one day truly became as fast as cuDNN—the core developers of PyTorch wouldn't instantly upgrade the AMD backend to a first-class citizen because of that. Because the primary contributors to PyTorch are at Meta. Meta's GPU clusters entirely use NVIDIA. Every new feature of PyTorch is developed, tested, and optimized on NVIDIA GPUs first, and only then does someone—usually AMD's own engineers—spend a few weeks adapting it to ROCm.
You are not chasing a stationary target. You are chasing a target that runs every day, and all the referees, spectators, and reporters on the track are cheering for that target.
Valve used Proton to pry open the DirectX lock. But that was because DirectX only locked one layer—an API layer whose behavior could be reversed and translated. What CUDA locks is not one layer. It locked the hardware instruction set, compute libraries, AI frameworks, and GPU computing courses at every university worldwide. Four locks stacked together, each deeper than DirectX. To this day, no one has been able to pry this lock open.
There is a contrast here so ironic it's cruel.
NVIDIA's closed-source strategy yielded completely opposite results on two battlefields.
The previous chapter stated: Valve chose AMD instead of NVIDIA as its chip partner for the Steam Deck precisely because NVIDIA's Linux GPU drivers were closed-source—Valve's engineers couldn't modify it, couldn't perform deep optimization targeting Proton, and couldn't achieve end-to-end integration between the translation layer and the driver layer. NVIDIA's closed-source strategy caused it to lose the battlefield of Linux gaming hardware.
But the exact same closed-source strategy—the closed-source nature of the CUDA ecosystem—allowed NVIDIA to win AI.
What's the difference? The difference is the depth of the lock.
DirectX only locks one layer of API. If you open up the GPU driver (which AMD did), the translation layer can talk directly to the hardware, making a closed-source driver an obstacle. But CUDA locks four layers. No matter how open-source AMD's driver is, it cannot touch the three layers above the driver—libraries, frameworks, and knowledge systems. The victory of open source at the driver layer is meaningless to CUDA's four-layer prison.
Open source vs closed source is not a moral judgment. It is a strategy. It depends on what you are locking, and how deep you are locking it. DirectX locks shallowly, so the open-source community could translate it. CUDA locks four layers deep; no matter how much open source wins at the bottom layer, the three layers above remain entirely unmoved.
IV. Recognition
Six years.
From the birth of CUDA with the GeForce 8800 GTX in 2006 to its ignition by a 27-year-old Ukrainian-Canadian PhD student in 2012—six years.
Alex Krizhevsky was doing his PhD at the University of Toronto. His advisor was Geoffrey Hinton—an outlier who for decades insisted that "neural networks will eventually return." Hinton's other student was Ilya Sutskever—the same Ilya Sutskever who would later co-found OpenAI and then leave to found Safe Superintelligence.
Krizhevsky had already written a convolutional neural network program in CUDA called cuda-convnet, running on small-scale datasets. Now he wanted to do something bigger: challenge ImageNet with a deep neural network—a massive image recognition dataset containing over 15 million labeled photos. The best accuracy rates of traditional machine learning methods on this dataset had been stagnant for several years.
His training equipment was two NVIDIA GTX 580s—consumer gaming graphics cards of the time, each with 3GB of VRAM (a special version of the GTX 580—the standard version only had 1.5GB, but Krizhevsky needed more memory to fit sixty million parameters), retailing for about $500. He installed these two cards in a desktop computer and placed it in his bedroom at his parents' house.
On September 30, 2012, the SuperVision team formed by him, Sutskever, and Hinton submitted their results to the ImageNet Large Scale Visual Recognition Challenge.
Their model—later named AlexNet—crushed the top-5 error rate from the runner-up's 26.2% down to 15.3%.
The gap wasn't a few percentage points. It was ten percentage points. In a competition where top global labs had competed fiercely for years, improving by less than one percentage point annually, a three-person team, using two gaming graphics cards in a bedroom, left everyone else in the dust by ten percentage points.
The entire field of computer vision changed direction that day.
But what truly changed wasn't the academic world. What truly changed was Jensen Huang's company.
AlexNet proved one thing: deep neural networks aren't just theoretically effective—they steamroll all traditional methods on massive datasets. And the critical hardware that enabled this steamrolling was the GPU. Not the CPU, not an FPGA, not any custom AI accelerator—but two gaming graphics cards you could buy at Best Buy for a thousand dollars.
NVIDIA transformed from a "gaming graphics card company" into an "AI infrastructure company" that autumn.
It didn't need to pivot. It didn't need to restructure. It didn't need to develop new products. Because it had already built the hardware six years prior—every GeForce had CUDA cores inside, and every one could run general-purpose computing. AlexNet merely found the masters those cores had been waiting for as they slumbered for six years.
Gamers had paid the R&D tax for six years. In the moment Krizhevsky pressed "Start Training" in his bedroom, the bill for that tax was settled.
V. Closing Arguments
This pattern appears again.
Chapter 2 is the prototype: Microsoft uses the convenience of DirectX to attract game developers → Developers are locked onto Windows → Consumers are locked in turn.
Chapter 6 is the counterattack plus a new lock: Valve uses Proton to pry open Microsoft's wall → Builds Steam's wall in the exact same spot.
This chapter is the fifth variation, and the deepest lock of all.
The entrance of convenience: more beautiful game visuals. Every generation of GeForce was faster than the last, and gamers willingly handed over their money to upgrade—$599, $699, $999, all the way to the RTX 4090's $1,599. They were buying visual quality. They didn't know that inside every card they bought was a set of general-purpose compute cores entirely unrelated to gaming, paving the way for NVIDIA's next game of chess.
The targets of lock-in: AI researchers. They weren't persuaded by NVIDIA's salespeople. They were persuaded by their paper advisors, by textbooks, by Stack Overflow, and by PyTorch's import torch. They didn't even feel like they were making a choice—CUDA wasn't a tool they chose to use; CUDA was the environment they grew up in. You wouldn't say you "chose the air."
The ultimately locked targets: every tech company in the world that wants to do AI. Google, Meta, Amazon, Microsoft, every Chinese tech giant, every AI startup—they are all locked in. Not because NVIDIA's GPUs are the best (although they are indeed the best), but because the entire AI ecosystem—from education to frameworks to libraries to hardware—all grew up revolving around CUDA. You could build a faster AI chip. But if the AI engineers of the world don't know how to use it, it's just an expensive piece of silicon.
The cost only materializes over a decade later.
In 2024, NVIDIA's market capitalization surpassed three trillion dollars. The H100 GPU—the card that trained ChatGPT and Claude—was out of stock globally. Tech companies lined up with multi-billion-dollar orders to buy that card from Jensen Huang. A single H100 retails between $25,000 and $40,000, depending on the model and supply and demand. How much of that price is the GPU hardware cost? How much is the monopoly premium of the CUDA ecosystem?
No one can clearly untangle it. Because CUDA's four-layer lock has already caused NVIDIA's GPU and the AI ecosystem to meld into one. You aren't buying a card—you are buying an admission ticket to the entire ecosystem. And the admission fee for this ecosystem was prepaid for you by gamers, graphics card by graphics card, starting in 2006.
VI. The Loot is Still Being Divided
Back to the young machine learning engineer at the beginning.
He tried to switch his company's GPU cluster from NVIDIA to AMD, spent two weeks, and gave up. He treated this as a technical problem—"AMD's software isn't mature enough yet."
But he was wrong. This isn't an issue of maturity. It is an issue of a system that was designed before he was born.
In 2006, the day Jensen Huang decided to stuff general-purpose compute cores into the GeForce 8800 GTX, the fate of this young engineer was already decided. His university professor would teach him parallel programming using CUDA, his first job would require him to train models using PyTorch, and his PyTorch would call cuDNN and cuBLAS underneath—and he will never know that this entire pipeline exists because, eighteen years ago, a group of gamers pursuing extreme visual quality shared an R&D cost they didn't know existed, for a company they didn't know.
Every cent of GPU rent he pays today, every H100 order his company places with NVIDIA, every dollar of monopoly premium the global AI industry pays to Jensen Huang—are all the delayed bills of that decision in 2006.
But the bill is not just money. There is another side to the bill.
Every NVIDIA GPU—whether it's a GeForce, Quadro, Tesla, or H100—is a silicon chip. Someone has to manufacture it. Someone has to carve its circuits. Someone has to implement its transistors on a twelve-inch silicon wafer using photolithography machines, etching fluids, and hundreds of precision processes.
In 2026, there is only one company that manufactures these chips. It is not in Silicon Valley, not in Tokyo, not in Seoul.
It is in Hsinchu.