第七章:CUDA 豪賭與遊戲玩家的「R&D 稅」
2026 年春天,一個剛拿到碩士學位的機器學習工程師,正在為他的第一份工作做技術選型。任務很簡單:訓練一個中等規模的語言模型。他打開 PyTorch,寫了幾行程式碼,呼叫了 torch.cuda.is_available(),確認 GPU 在線,然後開始訓練。
他沒有想過那行程式碼底下發生了什麼。
PyTorch 呼叫了 cuDNN——NVIDIA 的深度神經網路加速函式庫。cuDNN 呼叫了 cuBLAS——NVIDIA 的線性代數函式庫。cuBLAS 編譯成 PTX 中間碼,再被 NVIDIA 驅動程式即時翻譯成 SASS——那張 GPU 的原生機器指令。整條管線從第一行 Python 到最後一個電晶體的開關,每一層都印著同一個商標。
他的主管說:「公司預算吃緊,AMD 的 GPU 便宜四成。能不能換?」
他試了。把 torch.cuda 改成 torch.hip。第一個錯誤出現在 cuDNN 的某個卷積核心——AMD 的對應物 MIOpen 不支援那個特定的資料排列格式。他繞過去了。第二個錯誤出現在多 GPU 通訊——NVIDIA 的 NCCL 函式庫在 AMD 上沒有對等品,AMD 自己的 RCCL 效能差一截,某些拓撲下直接掛掉。他花了三天追蹤問題,發現是驅動程式層的一個 race condition,AMD 的 ROCm 團隊在 GitHub 上標記為「已知問題,預計下一版修復」。
兩週後,他跟主管說:「換不了。」
他把這件事當成一個工程問題——AMD 的軟體還不夠成熟,再等兩年或許就好了。
不是。
AMD 的 ROCm 不是「還不夠成熟」。它已經追了十年,依然追不上。不是因為 AMD 的工程師比 NVIDIA 的差,是因為他們面對的不是一道鎖,是一座四層深的監獄。而你——每一個用 PyTorch 訓練過模型的人——從讀碩士的第一天起,就住在裡面。
上一章講了一道鎖怎麼被撬開。DirectX 鎖了 PC 遊戲三十年,Valve 用 Proton 把它繞過去了。讀完那一章,你可能覺得:鎖都能撬開,只要有人夠執著。
這一章要打碎那個幻覺。
I. 作案動機
2003 年,一個叫 Ian Buck 的史丹佛大學博士生,發表了一樣東西。不是一張顯示卡,不是一款遊戲——是一個程式語言。
它叫 Brook。
Buck 在史丹佛圖形實驗室裡觀察到一個事實:GPU 裡面有幾百個小核心,每一個都能做浮點運算,合起來的算力遠超當時最快的 CPU。但這些核心只認得繪圖 API——它們被硬體設計綁死在「畫像素」這一件事上。如果能把它們拿來算別的東西——矩陣乘法、物理模擬、蛋白質摺疊——那會怎樣?
Brook 就是他給出的答案:一個讓程式設計師用類似 C 的語法,把通用運算任務丟到 GPU 上面跑的語言。概念很漂亮,但有一個致命問題:Brook 必須把所有運算任務偽裝成圖形渲染指令——因為當時的 GPU 硬體只認得繪圖 API。你想算一個矩陣乘法?你得先假裝它是一塊三角形�的紋理,然後用 OpenGL 的 shader 去「渲染」它。效率低,限制多,能做的事少。
Buck 靠 Brook 拿了學位。然後黃仁勳親自邀請他加入 NVIDIA。
2004 年,Buck 進了 NVIDIA。黃仁勳看了 Buck 的研究,看到的不是一篇學術報告——他看到的是一條縫。GPU 裡面有幾百個小核心,每一個都能做浮點運算,但硬體設計強迫它們只能畫圖。如果把這個限制拿掉——讓那些核心可以做任何運算——GPU 就會從一張繪圖卡變成一台超級電腦。
但拿掉限制的代價很大。它意味著重新設計 GPU 的整個架構:指令集要改、記憶體模型要改、執行緒排程器要改。而這些改動不會讓遊戲跑得更快——遊戲只需要畫圖,不需要通用運算。換句話說,改了之後,遊戲玩家拿不到任何好處,但 NVIDIA 要為這些改動付出巨額的研發成本。
黃仁勳讓 Buck 帶一支團隊,把 Brook 的概念直接燒進下一代 GPU 的硬體裡。不是用軟體模擬,不是用 shader hack——是在矽晶片上刻出真正的通用運算單元,讓每一個核心都能執行任意的 C 語言程式碼。
2006 年 11 月 8 日,GeForce 8800 GTX 上市。代號 G80。599 美元。128 個串流處理器,6.81 億個電晶體,90 奈米製程。
遊戲玩家看到的是:史上第一張支援 DirectX 10 的顯示卡,畫質的跳躍讓人目瞪口呆。
遊戲玩家沒看到的是:那 128 個串流處理器裡面,每一個都被重新設計過——它們不只能算像素,還能算任何東西。矩陣乘法、傅立葉轉換、流體力學模擬、分子動力學——只要你能寫成並行程式碼的問題,都可以丟上去。
七個月後,2007 年 6 月 26 日,NVIDIA 發佈 CUDA Toolkit 1.0——一套讓程式設計師直接用 C 語言在 GPU 上寫通用運算程式的開發工具。
沒有玩家注意到。沒有遊戲媒體報導。對 99% 的 GeForce 8800 GTX 用戶來說,CUDA 是一個不存在的東西。他們花 599 美元買了一張顯示卡,為的是玩遊戲,不是跑科學計算。
但他們的 599 美元裡面,有一部分被拿去分攤了通用運算核心的研發成本。
每一張賣出去的 GeForce,都內建了玩家用不到但科研界日後會用到的硬體。NVIDIA 沒有跟任何人解釋這件事。它不需要。它只需要繼續賣遊戲顯示卡——賣得越多,通用運算的研發成本被攤得越薄,風險就越低。
間章定義過一種人——看得穿硬體指令集、軟體 API、以及上層應用三個層次之間接縫的人。黃仁勳就是這種人的原型。他看得見 GPU 繪圖核心跟通用運算之間的那條縫。他下的賭注是:先讓遊戲玩家幫我養這條縫,等有一天,有人會來認領。
但這裡要停下來問一個問題:NVIDIA 不是 Valve。
上一章特別指出,Valve 能扛住 Steam Machine 失敗後繼續投資 Linux,是因為它是私人公司——沒有股東、沒有華爾街分析師每季度問你 ROI 在哪裡。但 NVIDIA 在 1999 年 1 月就已經上市了。它是一家 NASDAQ 掛牌的公眾公司。CUDA 的研發成本讓 NVIDIA 的市值從大約 80 億美元跌到不足 15 億美元。華爾街的反應不是質疑,是沉默——那是比質疑更可怕的東西。
黃仁勳憑什麼扛得住?
答案,要從第四章埋下的一條線說起。
第四章的結尾講過:NVIDIA 在 2001 年為初代 Xbox 供應了 GPU——代號 NV2A,基於 GeForce 3 架構。那是 NVIDIA 第一次嘗到主機市場的味道。味道很苦。微軟在合約裡鎖死了晶片價格,要求 NVIDIA 逐年降價。黃仁勳拒絕。雙方的關係從冷淡到仲裁,最終在 2003 年 2 月和解。但和解不是和好。2003 年 8 月,微軟宣佈 Xbox 360 的 GPU 改用 ATI。
NVIDIA 被踢出了客廳。
從商業教科書的角度看,這是一場失��敗。主機 GPU 是一條長達七到十年的穩定訂單管線——第八章會展開這一點。失去微軟這個客戶,等於失去一條幾千萬台出貨量的長期飯票。
但事後看,被踢出去,是黃仁勳職業生涯裡發生過的最好的事。
原因有三。
第一,主機 GPU 是一份吃力不討好的差事。 主機廠要求你把晶片做成半客製化的 SoC,塞進它們設計的機殼裡,按照它們的散熱預算跑,然後年年降價。你的頂級工程師不是在追求下一代架構的突破——他們在替微軟省成本。如果 NVIDIA 還在做 Xbox 360 的 GPU,2004 到 2006 年那些本該設計 CUDA 核心的工程師,很可能被鎖在為微軟壓縮成本的苦差事上。
第二,PC 顯示卡的利潤結構,比主機 GPU 好得不是一個等級。 微軟嫌一顆主機晶片幾十美元太貴。但 PC 玩家願意花 599 美元買一張 GeForce 8800 GTX——那是主機 GPU 單價的十幾倍。微軟不肯給的利潤,遊戲玩家雙手奉上。這些利潤,就是 CUDA 燒了十年而 NVIDIA 不會倒閉的真正原因。黃仁勳把 CUDA 的研發成本藏在每一張 GeForce 的毛利裡——玩家看不見,華爾街也不夠懂硬體設計,不知道那些「通用運算核心」是遊戲玩家用不到的東西。「R&D 稅」不只是一個比喻。它是黃仁勳瞞天過海的財務手段。
第三,失去客廳,迫使黃仁勳去想一個他本來不需要問的問題:GPU 除了畫遊戲,還能做什麼? 如果 NVIDIA 還有微軟的長期飯票,這個問題可能永遠不會被認真對待。但飯票沒了。黃仁勳必須為 GPU 找到遊戲以外的第二條命。Ian Buck 的 Brook,就是那條命的起點。
這裡有一個諷刺到令人窒息的迴旋。
2002 年,微軟為了在每顆 Xbox 晶片上省幾美元的成本,跟 NVIDIA 鬧翻。那幾美元乘以幾千萬台 Xbox,大約��是幾億美元的爭議。微軟覺得自己贏了——用更便宜的 ATI 晶片做了 Xbox 360,賣得比初代好。
二十年後,2023 年,微軟向 NVIDIA 下了一筆訂單。不是幾億美元——是幾十億美元。幾萬張 H100 和後續的 B200,用來訓練它投資了一百三十億美元的 OpenAI 的大型語言模型。每一張卡的售價,是當年那顆 Xbox GPU 成本的幾百倍。
當年微軟嫌貴踢走 NVIDIA 省下的那筆錢,如今連本帶利,全部嘔了回來。而且是跪著嘔的——因為 CUDA 的四層鎖意味著,微軟就算想換供應商,也換不了。
微軟是 CUDA 壟斷的間接催生者。 它踢走了 NVIDIA,逼黃仁勳退回 PC,退回 PC 讓 NVIDIA 賺到養 CUDA 的利潤,CUDA 長成了四層深的監獄,而微軟自己,成了這座監獄裡最大的一個囚犯。
這個「有一天」,他等了六年。
II. 武器鍛造
CUDA 不是一個 API。
第二章的 DirectX 是一個 API。它做一件事:讓遊戲程式設計師可以用一組統一的函式呼叫,驅動不同廠商的 GPU 畫圖。DirectX 是一層——一層介面,夾在遊戲引擎跟 GPU 驅動之間。
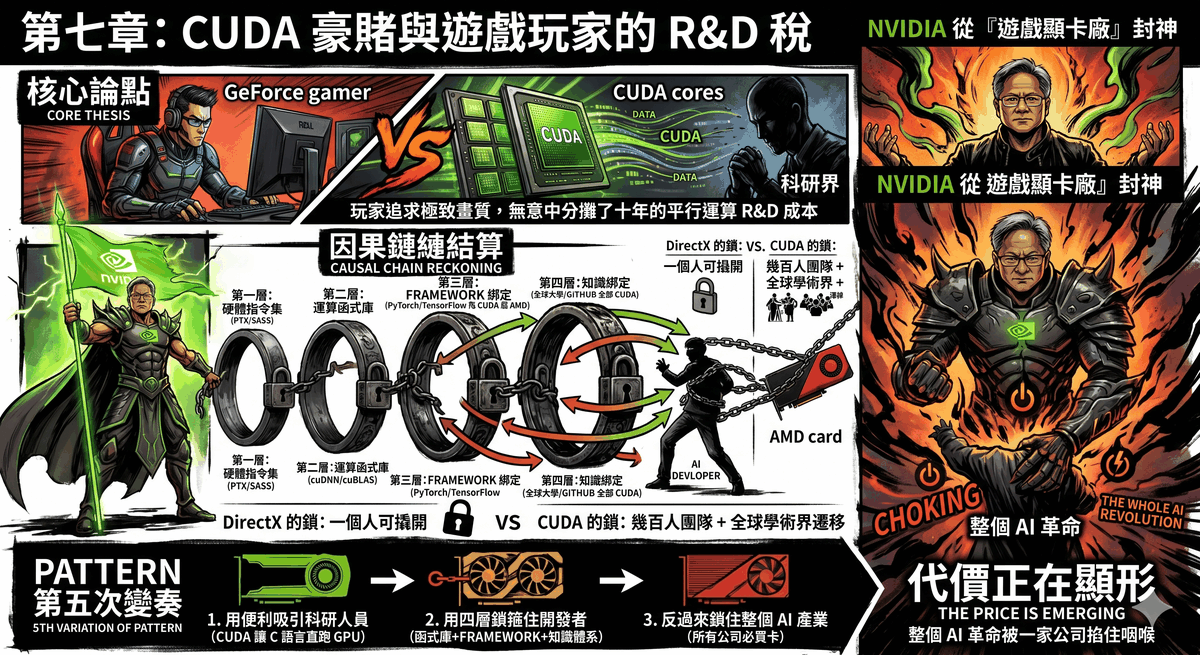
CUDA 不是一層。CUDA 是四層疊在一起的一座塔。每一層都有自己的鎖,每一把鎖都獨立運作,合起來構成一座幾乎不可能逃離的監獄。
第一層:硬體指令集。
NVIDIA 的 GPU 有自己的原生指令集——PTX(Parallel Thread Execution)是中間表達層,SASS 是最底層的機器碼。當你寫一段 CUDA 程式碼,編譯器把它變成 PTX,然後 NVIDIA 的驅動程式在執行時把 PTX 翻譯成你那張特定 GPU 型號的 SASS。
這跟 x86 CPU 的道理一樣:你的程式碼最終要變成那顆晶片聽得懂的指令。但差別在於,x86 的指令集是公開的——Intel 和 AMD 都實作同一套指令集,所以你的程式在兩家的 CPU 上都能跑。NVIDIA 的 PTX 和 SASS 是專屬的。AMD 的 GPU 有完全不同的指令集架構。你沒有辦法把一段已編譯的 CUDA 程式拿到 AMD GPU 上跑,就像你不能把一張 CD 塞進錄音機裡播放。
第二層:運算函式庫。
一個 AI 研究員不會自己寫矩陣乘法的 GPU 核心程式——太慢、太容易出錯、而且已經有人做過了。他會呼叫 cuBLAS——NVIDIA 的線性代數加速函式庫。訓練神經網路?cuDNN——NVIDIA 針對深度學習優化的卷積、正規化、激活函數加速庫。做傅立葉轉換?cuFFT。做稀疏矩陣運算?cuSPARSE。多 GPU 之間的通訊?NCCL。
每一個函式庫背後,都是一支幾十到幾百人的工程團隊,針對 NVIDIA 每一代 GPU 的微架構,花了五年、十年做極致優化。同一個矩陣乘法呼叫,在 cuBLAS 上跑的版本,會根據你的 GPU 型號、矩陣大小、資料型態,自動選擇最佳的演算法——這些演算法是工程師用手一個一個調出來的,不是程式自動生成的。
AMD 有對應的函式庫嗎?有。rocBLAS、MIOpen、rocFFT——名字都對得上,功能大致對得上。但它們起步晚了將近十年,而且它們要追的對象每一年都在繼續跑。cuBLAS 在 2026 年已經經歷了十幾個主要版本的迭代。rocBLAS 要追的不只是今天的 cuBLAS,還包括 cuBLAS 未來三年的路線圖。
追,但追不上。因為 NVIDIA 有一個 AMD 沒有的東西:全世界的 AI 研究員每天都在用 cuBLAS 跑實驗,回報 bug、要求功能、貢獻效能資料。 這個回饋迴路是 rocBLAS 買不到的——因為用 rocBLAS 的人太少。
第三層:框架綁定。
PyTorch。TensorFlow。JAX�。
2026 年全球 AI 研究界使用的三大框架。它們全部是先寫 CUDA 後端,再補 AMD 支援。
這句話看起來像是一個排程問題——先做哪個後做哪個。不是。這是一個深度綁定的問題。PyTorch 的核心運算子——那些做前向傳播、反向傳播、梯度更新的底層函式——最初是用 CUDA 寫的。它們不是呼叫一個抽象的 GPU API 再適配到 CUDA——它們直接用 CUDA 的記憶體模型、CUDA 的執行緒層級、CUDA 的同步原語來寫。AMD 的後端是事後加上去的,本質上是一個翻譯層,把 PyTorch 的 CUDA 呼叫翻譯成 AMD 的 HIP 呼叫。
翻譯能做到多少?基本功能可以。但邊界情況——某個罕見的 tensor 形狀觸發了 cuDNN 裡一條 NVIDIA 獨有的快速路徑、某個分散式訓練策略依賴 NCCL 的某個特定行為、某個自訂的 CUDA kernel 用了 NVIDIA 獨有的指令——這些地方就會斷。
一個 AI 研究員寫的訓練程式碼裡,有十幾個隱含的 CUDA 依賴。不是他自己寫的——是 PyTorch 替他呼叫的。他在程式碼裡寫 model.train(),PyTorch 替他呼叫了 cuDNN 的卷積核心、cuBLAS 的矩陣乘法、NCCL 的梯度同步。他根本不知道自己在用 CUDA——就像第六章 Steam Deck 的玩家不知道自己在用 Linux。差別在於,Steam Deck 的玩家可以不在乎底下是什麼;AI 研究員在想換 GPU 的那一刻,才發現自己被鎖在哪裡。
第四層:知識綁定。
這是最深的一層,也是最不容易被看見的一層。
全球大學的 GPU 計算課程——用 CUDA 教。教科書——用 CUDA 寫範例。學術論文的實驗程式碼——放在 GitHub 上,用 CUDA 實作。Stack Overflow 上關於 GPU 加速的問答——CUDA 的回答比 ROCm 多五十倍。一個博士生從入學第一天起,他學的並行運算語言就是 CUDA,他讀的論文附的程式碼就是 CUDA,他問問題得到的回�答就是 CUDA。
五年之後,他畢業了。他進了一家 AI 公司。他的思考方式——怎麼切分資料、怎麼安排執行緒、怎麼最小化記憶體搬運——全部是用 CUDA 的心智模型鍛造出來的。你跟他說「換 AMD」,他需要的不只是換一套工具鏈——他需要重新學一套思考方式。
而他不會。因為他的同事也都用 CUDA。他的論文審稿人也用 CUDA。他的下一份工作面試也問 CUDA。
這就是知識鎖定。它不靠任何合約、不靠任何專利、不靠任何商業條款。它靠的是一整個世代的工程師,在同一套工具裡長大。
四層鎖。硬體指令集、函式庫生態、框架綁定、知識綁定。每一層都獨立運作,每一層都有自己的護城河。你撬開了第一層(做出自己的 GPU 指令集),第二層還在(沒有對等的函式庫)。你追上了第二層(花十年寫出對等的函式庫),第三層還在(框架的核心程式碼依然先寫 CUDA)。你說服了框架開發者同等對待你(第三層),第四層還在——一百萬個已經用 CUDA 思考的 AI 工程師,不會因為你做了一套好工具就跟著你走。
這座監獄沒有明確的一道門。它是由四道互相加強的牆圍起來的。
III. 為什麼撬不開
讀完上一章,你可能覺得:CUDA 再難撬,也不過是另一個 DirectX——找到一個夠執著的工程師,花幾年時間做翻譯層,總能繞過去。
不能。
因為 DirectX 和 CUDA 的鎖,深度完全不同。
DirectX 鎖住的是一層——一層繪圖 API。它的行為雖然龐雜,但本質上是一組輸入輸出的對應關係:遊戲發出某個 Direct3D 呼叫,預期螢幕上出現某個結果。這組對應關係大部分有文件記載,剩下的可以逆向工程。DXVK 的開發者 Philip Rebohle——一個人——就能啟動這場反擊。因為他只需要做一件事:觀察 DirectX 的行為,用 Vulkan 複製出來。繁瑣,但可行。
CUDA 鎖住的不是一層。是四層。
AMD 試過翻譯。它做了 HIP——一套工具,可以把大部分 CUDA 原始碼自動轉換成 AMD 的程式碼。表層的轉換確實能做。但碰到 cuDNN——一個沒有原始碼的二進位函式庫——HIP 就斷了。你沒有辦法翻譯一個你看不到內部的東西。AMD 只能自己從頭寫一個功能對等的 MIOpen,然後花幾年時間追趕 cuDNN 每半年一次的更新。
更深的問題是:即使 AMD 在函式庫層面追上了——假設 MIOpen 有一天真的跟 cuDNN 一樣快——PyTorch 的核心開發者也不會因此就把 AMD 後端升級為一等公民。因為 PyTorch 的主要貢獻者在 Meta。Meta 的 GPU 叢集用的全是 NVIDIA。PyTorch 的每一個新功能,都是先在 NVIDIA GPU 上開發、測試、優化,然後才有人——通常是 AMD 自己的工程師——花幾週把它適配到 ROCm 上。
你追的不是一個靜止的靶。你追的是一個每天都在跑的靶,而且跑道上的裁判、觀眾和記者全都在替那個靶加油。
Valve 用 Proton 撬開了 DirectX 的鎖。但那是因為 DirectX 只鎖了一層——一層 API,行為可以逆向、可以翻譯。CUDA 鎖住的不是一層。它鎖住了硬體指令集、運算函式庫、AI 框架、以及全世界每一間大學的 GPU 計算課程。四把鎖疊在一起,每一把都比 DirectX 更深。這道鎖,到今天為止,沒有人撬得開。
這裡有一個諷刺到殘忍的對比。
NVIDIA 的閉源策略,在兩個戰場得到了完全相反的結果。
上一章說過:Valve 選擇 AMD 而不是 NVIDIA 做 Steam Deck 的晶片夥伴,正是因為 NVIDIA 的 Linux GPU 驅動是閉源的——Valve 的工程師沒辦法修改它、沒辦法針對 Proton 做深度優化、沒辦法在翻譯層和驅動層之間做端到端的整合。NVIDIA 的閉源策略,讓它輸掉了 Linux 遊戲硬體這個戰場。
但同一套閉源策略——CUDA 生態的閉源——讓 NVIDIA 贏了 AI。
差別在哪裡?差別在鎖的深度。
DirectX 只鎖一層 API。你把 GPU 驅動打開(AMD 做到了),翻譯層就能直接跟硬體對話,閉源驅動反而變成障礙。但 CUDA 鎖四層。AMD 的驅動再怎麼開源,也碰不到驅動上面那三層——函式庫、框架、知識體系。開源在驅動層的勝利,對 CUDA 的四層監獄毫無意義。
開源 vs 閉源不是道德判斷。是策略。 要看你鎖的是什麼、鎖得多深。DirectX 鎖得淺,所以開源社群翻譯得了。CUDA 鎖得深到四層,開源在最底層再怎麼贏,上面三層依然紋風不動。
IV. 相認
六年。
從 2006 年 CUDA 隨 GeForce 8800 GTX 降生,到 2012 年一個 27 歲的烏克蘭裔加拿大博士生把它引爆——六年。
Alex Krizhevsky 在多倫多大學讀博士。他的指導教授是 Geoffrey Hinton——一位幾十年來堅持「神經網路終將復興」的異類。Hinton 的另一個學生是 Ilya Sutskever——日後共同創辦 OpenAI、再出走創辦 Safe Superintelligence 的那個 Ilya Sutskever。
Krizhevsky 之前就已經用 CUDA 寫過一個卷積神經網路程式叫 cuda-convnet,在小規模資料集上跑。現在他想做一件更大的事:用深度神經網路挑戰 ImageNet——一個包含超過一千五百萬張標記照片的巨型圖像辨識資料集。傳統的機器學習方法在這個資料集上的最佳準確率已經停滯了好幾�年。
他的訓練設備是兩張 NVIDIA GTX 580——那時候的消費級遊戲顯示卡,每張 3GB 視訊記憶體(GTX 580 的特規版本——標準版只有 1.5GB,但 Krizhevsky 需要更多記憶體來塞下六千萬個參數),零售價大約 500 美元。他把這兩張卡裝在一台桌上型電腦裡,放在他父母家的臥室裡。
2012 年 9 月 30 日,他和 Sutskever、Hinton 三人組成的 SuperVision 團隊,把結果提交到 ImageNet 大規模視覺辨識挑戰賽。
他們的模型——後來被叫做 AlexNet——把 top-5 錯誤率從第二名的 26.2% 壓到 15.3%。
差距不是幾個百分點。是十個百分點。在一個全球頂尖實驗室激烈競爭了好幾年、每年進步不到一個百分點的比賽裡,一支三人團隊,用兩張遊戲顯示卡,在一間臥室裡,把所有人甩開了十個百分點。
整個計算機視覺領域在那一天改變了方向。
但真正改變的不是學術界。真正改變的,是黃仁勳的公司。
AlexNet 證明了一件事:深度神經網路不只是理論上有效——它在大規模資料集上碾壓了所有傳統方法。而讓它碾壓的關鍵硬體,是 GPU。不是 CPU、不是 FPGA、不是任何客製化的 AI 加速器——是兩張在百思買花一千美元就能買到的遊戲顯示卡。
NVIDIA 從一家「遊戲顯示卡公司」,在那一個秋天,變成了一家「AI 基礎設施公司」。
它不需要轉型。它不需要重組。它不需要開發新產品。因為它六年前就已經把硬體做好了——每一張 GeForce 裡面都有 CUDA 核心,每一張都能跑通用運算。AlexNet 只是替那些沉睡了六年的核心,找到了它們一直在等的主人。
遊戲玩家交了六年的 R&D 稅。在 Krizhevsky 臥室裡按下「開始訓練」的那一瞬間,這筆稅的帳單,結清了。
V. 結案陳詞
這個 pattern 又出現了。
第二章是原型:微軟用 DirectX 的便利吸引遊戲開發者 → 開發者被鎖進 Windows → 消費者跟著被鎖。
第六章是反擊加新鎖定:Valve 用 Proton 撬開微軟的牆 → 在原地蓋了 Steam 的牆。
這一章是第五次變奏,也是鎖定最深的一次。
便利的入口:更漂亮的遊戲畫質。每一代 GeForce 都比上一代快,遊戲玩家心甘情願地掏錢升級——599 美元、699 美元、999 美元、最後到 RTX 4090 的 1,599 美元。他們買的是畫質。他們不知道自己買的每一張卡裡面,都有一組跟遊戲無關的通用運算核心,正在替 NVIDIA 的下一盤棋鋪路。
鎖定的對象:AI 研究員。他們不是被 NVIDIA 的業務員說服的。他們是被自己的論文指導教授、被教科書、被 Stack Overflow、被 PyTorch 的 import torch 說服的。他們甚至不覺得自己做了選擇——CUDA 不是一個他們選擇使用的工具,CUDA 是他們成長的環境。你不會說自己「選擇了空氣」。
被鎖住的最終對象:全球每一家想做 AI 的科技公司。Google、Meta、Amazon、Microsoft、每一家中國科技巨頭、每一個 AI 新創——它們全部被鎖住了。不是因為 NVIDIA 的 GPU 最好(雖然確實最好),而是因為整個 AI 生態——從教育到框架到函式庫到硬體——全部是繞著 CUDA 長出來的。你可以造一張更快的 AI 晶片。但如果全世界的 AI 工程師都不會用它,它就是一塊昂貴的矽。
代價,要等十幾年後才顯形。
2024 年,NVIDIA 的市值突破三萬億美元。H100 GPU——訓練 ChatGPT 和 Claude 的那張卡——全球缺貨。科技公司排隊用幾十億美元的訂單,向黃仁�勳買那張卡。一張 H100 的售價在兩萬五千到四萬美元之間,取決於型號和供需。這個價格裡有多少是 GPU 硬體成本?有多少是 CUDA 生態的壟斷溢價?
沒有人拆得清。因為 CUDA 的四層鎖,已經讓 NVIDIA 的 GPU 和 AI 生態融為一體。你買的不是一張卡——你買的是整個生態的入場券。而這個生態的入場費,是遊戲玩家從 2006 年開始、一張一張顯示卡地替你預付的。
VI. 贓物仍在被瓜分
回到開篇那個年輕的機器學習工程師。
他試著把公司的 GPU 叢集從 NVIDIA 換成 AMD,花了兩週,放棄了。他把這件事當成一個技術問題——「AMD 的軟體還不夠成熟。」
但他錯了。這不是成熟度的問題。這是一個在他出生之前就被設計好的系統的問題。
2006 年,當黃仁勳決定在 GeForce 8800 GTX 裡塞入通用運算核心的那一天,這個年輕工程師的命運就已經被決定了。他的大學教授會用 CUDA 教他寫並行程式、他的第一份工作會要求他用 PyTorch 訓練模型、他的 PyTorch 底下會呼叫 cuDNN 和 cuBLAS——而他永遠不會知道,這整條管線之所以存在,是因為十八年前有一群追求極致畫質的遊戲玩家,替一家他們不認識的公司,分攤了一筆他們不知道存在的研發成本。
他今天付的每一分 GPU 租金、他的公司向 NVIDIA 下的每一筆 H100 訂單、全球 AI 產業向黃仁勳繳的每一元壟斷溢價——都是 2006 年那個決定的延遲帳單。
但帳單不只是錢。帳單還有另一面。
每一張 NVIDIA GPU——不論是 GeForce、Quadro、Tesla、還是 H100——都是一塊矽晶片。它要有人製造。它的電路要有人刻。它的電晶體要有人用光刻機、蝕刻液、幾百道精密工序,在一片十二吋的矽晶圓上實現。
2026 年,製造這些晶片的公司只有一家。它不在矽谷、不在東京、不在首爾。
它在新竹。